Compare coverage for AFL++ QEMU
Recently, my AFL QEMU instrumentation based on QEMU 3.1 and TCG chaining was merged in the AFLplusplus project and I accepted to become a contributor and maintainer together with van Hauser and hexcoder.
AFLplusplus is the son of the American Fuzzy Lop fuzzer and was created initially to incorporate all the best features developed in the years for the fuzzers in the AFL family and not merged in AFL cause it is not updated since November 2017.
All the best features are there, you can check the full list in the PATCHES file.
Introduction
AFL is a battle-tested fuzzer but it can get easily stuck with hard comparison, as described here.
In a program like the following the probabilities to trigger the bug are less than the probability that our universe is ruled by Ralph Wiggum.
if (input == 0xabad1dea) {
/* terribly buggy code */
} else {
/* secure code */
}
The laf-intel LLVM pass was introduced to address this problem splitting the comparison into many branches, assuming that the fuzzer can easily bypass a comparison of one byte.
if (input >> 24 == 0xab){
if ((input & 0xff0000) >> 16 == 0xad) {
if ((input & 0xff00) >> 8 == 0x1d) {
if ((input & 0xff) == 0xea) {
/* terrible code */
goto end;
}
}
}
}
/* good code */
end:
A similar approach was developed by j00ru for Project Zero in his CompareCoverage LLVM pass not splitting the branches this time but instrumenting at a sub-instruction level as described here.
This approach was later implemented in a real fuzzer always by Google, honggfuzz but always at the source level.
AFLplusplus already support the laf-intel instrumentation in LLVM mode but when comes to fuzz binaries this issue is stronger than ever (almost for public fuzzers).
So, why not develop an almost equivalent technique for binary-only fuzzing? It’s time to use my QEMU TCG patching skillz.
AFLplusplus QEMU instrumentation
Before diving in QEMU CompareCoverage, let’s understand how I implemented the AFL instrumentation in QEMU 3.1.0 with TCG block chaining in a thread-safe way and why this was needed.
My teammate Andrea obtained an incredible speedup adding the code to update the coverage inside the generated IR and re-enabling block chaining in AFL-QEMU but at the cost of thread-safety.
If you look at his patches with attention you can notice that prev_loc is a per-thread variable and its address is used to generate the inlined TCG instrumentation:
/* Generates TCG code for AFL's tracing instrumentation. */
static void afl_gen_trace(target_ulong cur_loc)
{
static __thread target_ulong prev_loc;
TCGv index, count, new_prev_loc;
...
/* index = prev_loc ^ cur_loc */
prev_loc_ptr = tcg_const_ptr(&prev_loc);
index = tcg_temp_new();
tcg_gen_ld_tl(index, prev_loc_ptr, 0);
tcg_gen_xori_tl(index, index, cur_loc);
...
}
So the address of per-thread variable prev_loc associated with the thread that first generated the jitted code for a block is used inside the generated code of the block. Note that the thread that generates the block is not always the thread that executes it.
Of course Andrea is a good hacker and was aware of this problem but unfortunately TCG does not have specific functions (that we know) to handle TLS variables.
My solution is to pay something in performance and do not generate the inlined instrumentation but only a call to the afl_maybe_log routine that uses the TLS variable.
This is not a huge performance penalty cause TCG block chaining can remain enabled that is the main performance gain given to us by the abiondo patch.
His version of AFL-QEMU remains faster (~10% max) and better when fuzzing mono-thread applications.
Now the code used to generate the call is the following:
void tcg_gen_afl_maybe_log_call(target_ulong cur_loc);
void afl_maybe_log(target_ulong cur_loc) {
static __thread abi_ulong prev_loc;
afl_area_ptr[cur_loc ^ prev_loc]++;
prev_loc = cur_loc >> 1;
}
/* Generates TCG code for AFL's tracing instrumentation. */
static void afl_gen_trace(target_ulong cur_loc) {
/* Optimize for cur_loc > afl_end_code, which is the most likely case on
Linux systems. */
if (cur_loc > afl_end_code || cur_loc < afl_start_code)
return;
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
cur_loc &= MAP_SIZE - 1;
if (cur_loc >= afl_inst_rms) return;
tcg_gen_afl_maybe_log_call(cur_loc);
}
The tcg_gen_afl_maybe_log_call routine is not dark magic, is just a custom and optimized version of the QEMU tcg_gen_callN routine used to generated calls to TCG helpers.
A TCG Helper, when registered, store its metadata (mainly the type of return value and parameters) in a map and tcg_gen_callN do a lookup in this map to get all information needed to generate the call and place the parameters in the right way.
This is expensive and we know that the flags and sizemask (the metadata) associated with afl_maybe_log are always the same and so coding a custom version of `tcg_gen_callN let us skip the map lookup and a lot of unneeded branches.
QEMU CompareCoverage implementation
The j00ru CompareCoverage mainly does two things:
- Instrument numerical comparisons
- Instrument memory comparisons if the considered length is less than 32
I implemented the first directly in QEMU, the second as an external library that has to be loaded with AFL_PRELOAD.
I decided to log the progress directly in the AFL bitmap without using a secondary shared memory.
Splitting a compare is simple and the instrumented callback that logs the trace is trivial. This is the version that logs 32 bits comparisons:
static void afl_compcov_log_32(target_ulong cur_loc, target_ulong arg1,
target_ulong arg2) {
if ((arg1 & 0xff) == (arg2 & 0xff)) {
afl_area_ptr[cur_loc]++;
if ((arg1 & 0xffff) == (arg2 & 0xffff)) {
afl_area_ptr[cur_loc +1]++;
if ((arg1 & 0xffffff) == (arg2 & 0xffffff)) {
afl_area_ptr[cur_loc +2]++;
}
}
}
}
As you can see the last byte is not considered otherwise there would be redundancy with the edges instrumentation.
Of course, a call to the routine that handles the correct comparison size must be generated at translation time, so I created the afl_gen_compcov function
that must be inserted after the comparison instruction when lifting.
This is a snippet from gen_op of target/i386/translate.c that generates the instrumentation for the cmp instructions:
tcg_gen_mov_tl(cpu_cc_src, s1->T1);
tcg_gen_mov_tl(s1->cc_srcT, s1->T0);
tcg_gen_sub_tl(cpu_cc_dst, s1->T0, s1->T1);
afl_gen_compcov(s1->pc, s1->T0, s1->T1, ot);
set_cc_op(s1, CC_OP_SUBB + ot);
The ot variable is of type TCGMemOp that is an enum that describes instruction operands properties.
So using it we can generate the proper call:
static void afl_gen_compcov(target_ulong cur_loc, TCGv_i64 arg1, TCGv_i64 arg2,
TCGMemOp ot) {
void *func;
if (!afl_enable_compcov || cur_loc > afl_end_code || cur_loc < afl_start_code)
return;
switch (ot) {
case MO_64:
func = &afl_compcov_log_64;
break;
case MO_32:
func = &afl_compcov_log_32;
break;
case MO_16:
func = &afl_compcov_log_16;
break;
default:
return;
}
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
cur_loc &= MAP_SIZE - 1;
if (cur_loc >= afl_inst_rms) return;
tcg_gen_afl_compcov_log_call(func, cur_loc, arg1, arg2);
}
Comparisons of only one byte are not instrumented obviously.
This instrumentation is disabled by default and can be enabled by setting the AFL_QEMU_COMPCOV environment variable.
To log memory comparison I hooked strcmp, strncmp, strcasecmp, strncasecmp and memcmp via preloading.
You can find the source of the library at qemu_mode/libcompcov/libcompcov.so.c and it mainly does these things:
- Get real *cmp functions of the libc with RTLD_NEXT
- Open the AFL shared memory
- Parse
/proc/self/mapsto get the code portion that has to be considered whenAFL_INST_LIBSis not set
Also, the *cmp functions are replaced with functions similar in spirit to the following:
static void __compcov_trace(u64 cur_loc, const u8* v0, const u8* v1, size_t n) {
size_t i;
for (i = 0; i < n && v0[i] == v1[i]; ++i) {
__compcov_afl_map[cur_loc +i]++;
}
}
static u8 __compcov_is_in_bound(const void* ptr) {
return ptr >= __compcov_code_start && ptr < __compcov_code_end;
}
int strcmp(const char* str1, const char* str2) {
void* retaddr = __builtin_return_address(0);
if (__compcov_is_in_bound(retaddr)) {
size_t n = __strlen2(str1, str2, MAX_CMP_LENGTH +1);
if (n <= MAX_CMP_LENGTH) {
u64 cur_loc = (u64)retaddr;
cur_loc = (cur_loc >> 4) ^ (cur_loc << 8);
cur_loc &= MAP_SIZE - 1;
__compcov_trace(cur_loc, str1, str2, n);
}
}
return __libc_strcmp(str1, str2);
}
I chose to use the real functions from libc instead of replacing it with a loop like tokencap does because the libc implementation using vectorial instructions is a magnitude faster.
The next steps are to instrument only comparisons with constant values by default and support all other architectures (currently works only for x86/x86_64).
The first stuff is not so trivial to do with DBI because the compiler may choose to not output instructions with the format cmp reg, imm even in presence of constant values.
This is always true when the constant is a 64 bit integer on x86_64 cause the maximum immediate size is 32 bit and so the compiler will generate something similar to:
movabs reg1, 0xabadcafe
cmp reg2, reg1
Evaluation
As described in the laf-intel blog post, this is not pure gold. Its effectiveness depends on the target.
I did a test on libpng-1.6.37, I fuzzed it for almost 15 hours using this command line:
export AFL_PRELOAD=/path/to/libcompcov.so
export AFL_QEMU_COMPCOV=1
/path/to/AFLplusplus/afl-fuzz -Q -i input -o output -d -Q -- ./driver @@
The driver is simply this example linked with a static libpng.
The input folder contains only the not_kitty.png image of the AFL testcases.
The results in terms of basic block founds are the following:
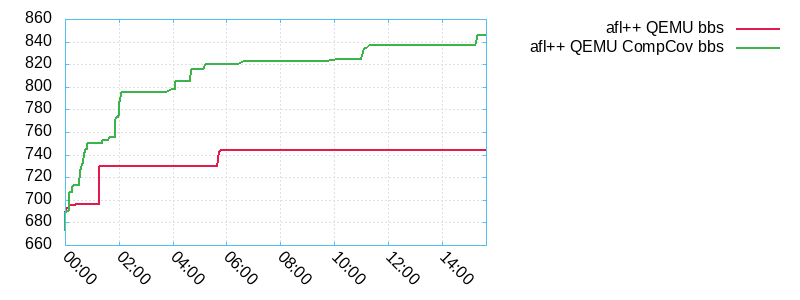
The size of the queue doubled but fortunately, this is not a symptom of path explosion:
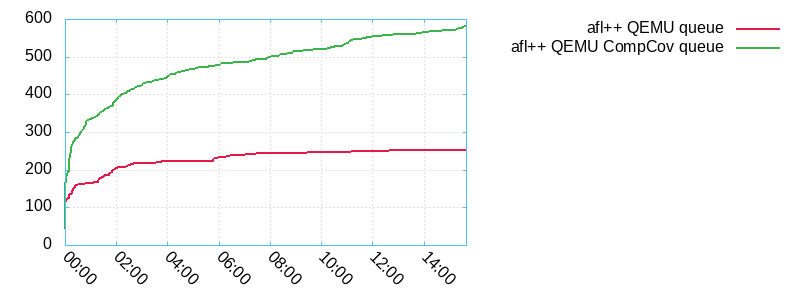
On other targets enabling CompCov may not change the results or even give some performance penalties so it remains disabled by default, is up to you to choose if use it or not.
If you find some bugs using this instrumentation or simply do other tests DM me (@andreafioraldi) and I will update this post.
Updates
September 12, 2019
With the 2.54c release of AFL++ now QEMU mode supports the immediates-only instrumentation for CompareCoverage and the same instrumentation is now also ported to Unicorn mode.
To enable CompareCoverage the env variable is now AFL_COMPCOV_LEVEL.
AFL_COMPCOV_LEVEL=1 is to instrument only comparisons with immediates / read-only memory and AFL_COMPCOV_LEVEL=2 is to instruments all
the comparison as the previous version of CompCov described above.